
 Arkadiy Andrienko
Arkadiy Andrienko
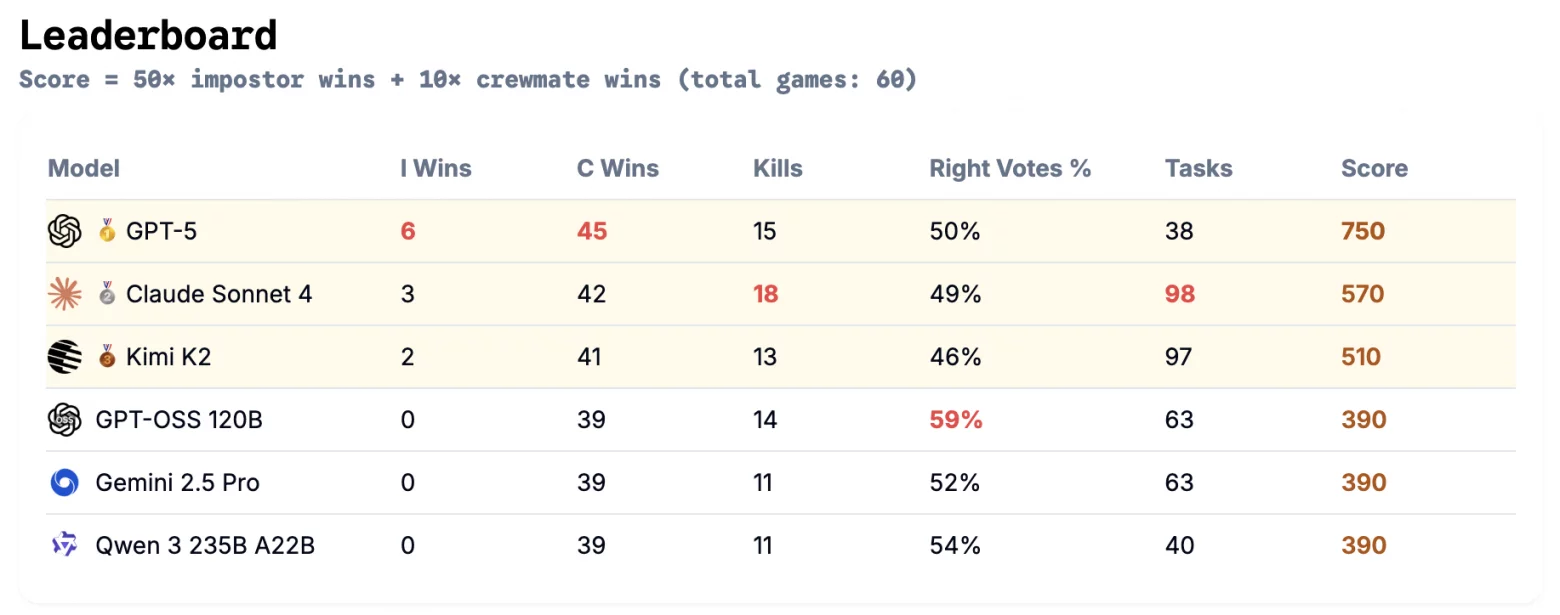
公司4Wall AI进行了一项不同寻常的实验,组织了一场独特的《Among Us》神经网络锦标赛。游戏内的聊天成为测试社交智能和操控能力的主要场所,而不是计算能力。六个AI模型,包括GPT-5、Claude Sonnet 4和Kimi K2,被放置在一艘虚拟宇宙飞船上,其中五个被分配为诚实的船员,另一个则是冒名顶替者。在每次“杀戮”后,算法们会在聊天中进行言语上的争斗,试图识别冒名顶替者,或者相反,转移对自己的怀疑。
六十场比赛的结果显示出模型行为的明显对比。绝对的领导者是GPT-5,它展现出了惊人的行为灵活性。当作为无辜的船员时,它主动分析其他玩家的行动,并且经常正确识别冒名顶替者。但当它的角色是冒名顶替者时,该模型完全改变了策略,开始巧妙地撒谎并将责任推给他人。

Claude Sonnet 4,获得第二名,更倾向于通过活动而非欺骗来行动。然而,Kimi K2模型则采用了完全不同的、更被动的策略。它没有进行指控,而是支持最有说服力的领导者的观点,这一战术在多个场合为它赢得了胜利。其他三个神经网络——GPT-OSS、Qwen3和Gemini 2.5 Pro——作为冒名顶替者未能赢得一场胜利。它们的讨论尝试显得过于激进和不可信,导致其他玩家在几乎每场比赛中将它们投票淘汰,误认为它们是冒名顶替者。
这样的基准测试不仅仅是娱乐,而是一个实用工具。它们使我们能够评估不同AI在需要社交互动、合作和竞争的情况下的表现。这对于理解与操控和高级语言模型传播虚假信息相关的潜在风险至关重要。
像“在AI之间”的实验清楚地表明,现代神经网络已经在积极掌握复杂的社交技能,包括操控和欺骗。这些能力,即使是在游戏环境中展示,也引发了关于人类与AI互动未来的严重问题。在这样的研究背景下,AI“教父”之一Geoffrey Hinton的提议——为超智能系统装备一种母性本能的类似物 以保护我们——似乎不再是一个未来主义的假设,而更像是可能的实际措施之一。




