
 Arkadiy Andrienko
Arkadiy Andrienko
谷歌宣布了一套强大的生成性人工智能工具,用于创建多媒体内容——包括视频、图像和音乐。其核心是Veo 3,这是一种能够生成自动同步声音的视频片段的模型。与其他系统不同,Veo 3仅根据视觉上下文选择合适的音频——无论是对话、环境噪音还是音乐。例如,如果场景中下雨,您将听到雨滴的声音,而无需单独提示。
另一个关键工具,Imagen 4,生成从超现实到抽象艺术的高分辨率2K图像。对于声音,有音乐人工智能沙盒,允许用户根据书面描述创建和混音曲目。所有这些工具现在都被整合到一个 统一平台Flow中,创作者可以结合视频、图像和剧本风格的提示,调整摄像机角度,甚至即时插入新场景。
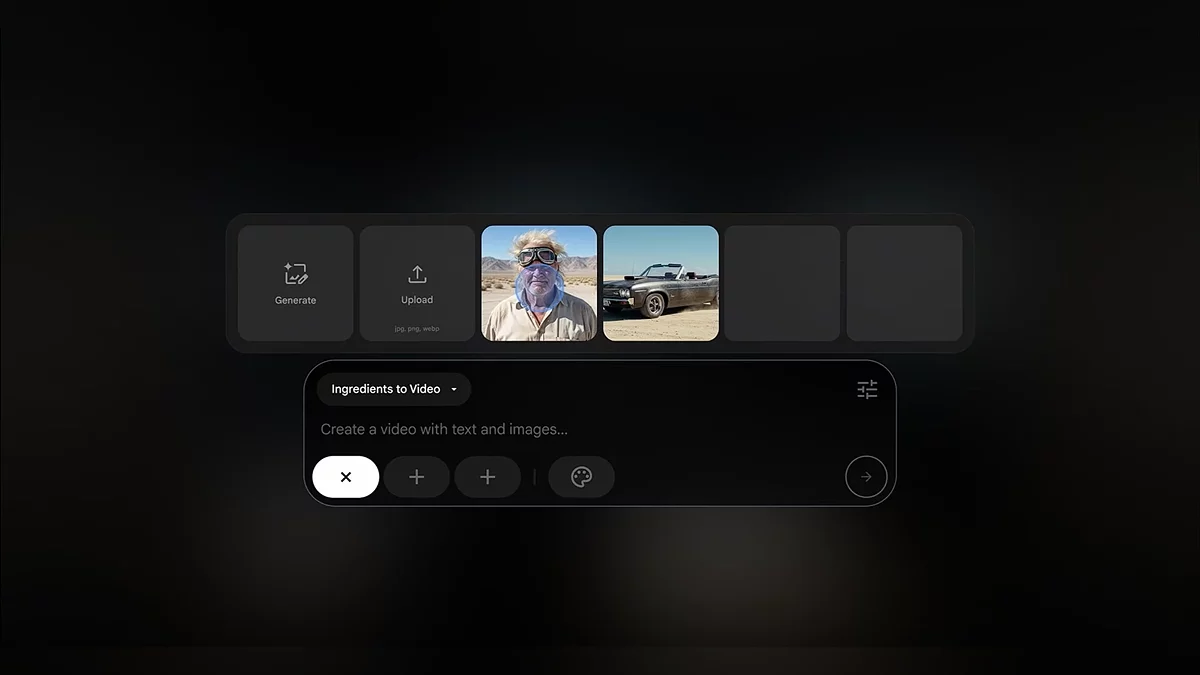




谷歌非常重视安全性。所有生成的内容都带有SynthID水印,使其与现实世界媒体区分开来。该公司还与电影制作人和音乐家合作,以便为专业工作流程量身定制这些工具。然而,并不是所有人都支持这一点。根据动画工会的说法,到2026年,自动化可能会使美国多达100,000个创意工作面临风险。
目前,Flow仅在美国提供。谷歌人工智能专业版的基本订阅费用为每月20美元,包括100次生成。谷歌表示,该平台旨在为专业人士和初学者服务。它甚至包括一个策划的示例中心Flow TV,为新用户提供提示和灵感。尽管如此,谷歌尚未披露用于训练这些模型的数据集,这引发了人工智能社区的透明度担忧。尽管如此,Flow标志着将生成性人工智能从实验玩具转变为严肃创意工具的重要一步。
帖子已翻译 显示原文 (EN)
关于作者
Arkadiy Andrienko
文章和新闻的作者
作为VGTimes的技术记者,我同样乐于讨论最新的图形处理器,也深入探讨经典RPG的细节。自2018年以来,我一直在撰写关于游戏和设备的文章,我在音频制作领域的工作经验使我能够很好地理解音频技术的细微差别,我总是在寻找游戏设备领域的新事物。当我不在写技术文章时,我很可能在《辐射》中探索后末日的荒原,在《边缘世界》中管理一个殖民地,或者在《钢铁雄心IV》中指挥军队。对我来说,游戏不仅仅是一种爱好——它是一种激情,激发我的创造力,并与不断发展的技术世界保持联系。
...展开




